Windows API hooking with Rust on Windows ARM
Lynx March 26, 2025 #MalDev #Rust #Windows API HookingIn this blog post, I will explore Windows API hooking on Windows 11 ARM using Rust. I'll present two distinct API hooking methods and delve into the specific challenges of implementing hooks on ARM-based Windows systems. Furthermore, I will provide a concise overview of the ARM64 architecture specifications that are essential for implementing API hooking in this environment.
API Hooking
Hooking refers to the technique of modifying software behavior by intercepting function calls or events generated by that software. In a previous post, I detailed how to use SetWindowsHookEx to intercept and respond to system events. Here, however, the focus shifts to function hooking, a technique that allows for intercepting calls to virtually any function. This capability enables the execution of custom code whenever a targeted function is called, offering significant control over program behavior.
Function or API hooking is achieved by altering the code of a function before a program calls it. The fundamental concept is that when a program attempts to execute a function, for example, Foo, the execution is redirected to a user-defined function – often referred to as a hook function, like FooHook. Within FooHook, you can insert custom code that will be executed. Following the execution of your hook code, you can decide whether to return execution to the original Foo function or not.
In many API hooking scenarios, returning to the original function's execution flow is desired, but it's not always necessary. The decision depends entirely on the specific objectives of the hook.
The diagrams below illustrate the execution flow differences between calling a hooked function versus an unhooked function, clarifying this redirection process.

Why use API hooking?
Now that you have a general understanding of what hooking is, let's explore why you might want to hook API functions and what you can actually achieve by doing so. While I mentioned earlier that hooking allows you to execute arbitrary code during a function call, let's refine that and illustrate with concrete examples to truly grasp the potential.
Function hooking provides the powerful ability to inspect and even modify function parameters. Imagine you are developing a simple EDR (Endpoint Detection and Response) solution. A key requirement might be to prevent malicious programs from stopping your EDR process itself. How can you ensure your EDR remains running? One effective approach is to hook the TerminateProcess function in all running processes. By doing this, you can examine every call to TerminateProcess. Whenever a process attempts to call TerminateProcess with your EDR's process name, let's say edr.exe, as the target, you can intercept this. You then have the choice to immediately prevent the termination by simply returning from the hooked function, or even take more drastic action, like terminating the process that attempted to terminate your EDR in the first place!

Consider another scenario: building your own sandbox environment for malware analysis. You're likely aware that malware may use the Sleep function to introduce delays in its execution. This is done to evade automated analysis in sandboxes, which often have time limits. To make your sandbox more robust against such evasion techniques, you can hook the Sleep function. By hooking Sleep, you can modify its behavior so that it always executes Sleep(0), regardless of the original sleep duration requested by the malware. Alternatively, you could completely disable the sleep functionality altogether within your sandbox.

So, you now have a glimpse into the "what" and "why" of API hooking. The next logical question is: how is this actually done? How do you successfully redirect execution from a function like Sleep to your custom MySleep function when a program calls Sleep? This is where the concept of a "detour jump," or simply "hook," truly comes into play.
Detour Jump / Hook
"Detour jump" or "hook" are terms for a sequence of assembly instructions designed to redirect program execution to a user-defined location. In our context, this means jumping to a custom function that executes either before or instead of the original Windows API function.
Let's examine the original assembly code of the MessageBoxA function:
USER32!MessageBoxA:
00007ffb`a73904a0 f0000888 adrp x8,USER32!gSharedInfo+0x20 (00007ffb`a74a3000)
00007ffb`a73904a4 b945a908 ldr w8,[x8,#0x5A8]
00007ffb`a73904a8 34000168 cbz w8,USER32!MessageBoxA+0x34 (00007ffb`a73904d4)
00007ffb`a73904ac aa1203e8 mov x8,xpr
00007ffb`a73904b0 f940250a ldr x10,[x8,#0x48]
00007ffb`a73904b4 900008a8 adrp x8,USER32!WPP_MAIN_CB+0x18 (00007ffb`a74a4000)
00007ffb`a73904b8 911b0109 add x9,x8,#0x6C0
00007ffb`a73904bc d2800008 mov x8,#0
This code snippet represents the initial instructions of MessageBoxA on an ARM64 system, which is the architecture of my research environment.
Now, observe how the code changes after hooking MessageBoxA using the Microsoft Detours library:
USER32!MessageBoxA:
00007ffb`a73904a0 90dfff91 adrp xip1,00007ffb`67380000
00007ffb`a73904a4 f9416e31 ldr xip1,[xip1,#0x2D8]
00007ffb`a73904a8 d61f0220 br xip1
00007ffb`a73904ac aa1203e8 mov x8,xpr
00007ffb`a73904b0 f940250a ldr x10,[x8,#0x48]
00007ffb`a73904b4 900008a8 adrp x8,USER32!WPP_MAIN_CB+0x18 (00007ffb`a74a4000)
00007ffb`a73904b8 911b0109 add x9,x8,#0x6C0
00007ffb`a73904bc d2800008 mov x8,#0
The first three instructions are modified to implement the hook. Specifically, the operands of the first two instructions are changed, and the third instruction, cbz, is replaced with br, a branch instruction. This br instruction redirects execution to the address stored in the xip1 register. In this hooking scenario, xip1 contains the address of the hook function for MessageBoxA.
Effectively, hooking a function involves overwriting the function's original code at the beginning with instructions that jump to your desired hook function. In the upcoming section, I will demonstrate how to create a rudimentary hook in Rust.
Naive Hooking
I call this approach "naive" because in this hook routine, I will restore the original bytes of the hooked function, effectively performing an unhook procedure within the hook routine itself. This method isn't ideal for persistent hooking as it introduces a potential performance bottleneck and a memory fingerprint. WriteProcessMemory will be used each time the function is invoked to perform unhooking. Furthermore, after each invocation of the hooked function, it must be hooked again to intercept subsequent calls to that function.
Moreover, a race condition can occur if another thread attempts to call the hooked function while the program is in the process of hooking or unhooking. This could lead to a situation where the function is called when it's only partially patched. For example, if only one instruction of the detour jump is written when another thread calls a hooked function, the function will be in an inconsistent state, potentially causing unpredictable behavior or crashes. This is a critical issue. The solution is to perform patching and unpatching of the function code within a single atomic transaction. By ensuring atomicity, other threads are prevented from executing the function during patching, guaranteeing either a fully patched or completely unpatched state. Although error handling during byte-by-byte patching is a concern, using transactions ensures that if any part of the operation fails, no changes are applied. For simplicity, my example will omit transaction management. For those interested in robust transactional hooking mechanisms, the Microsoft Detours library is a great source, as it offers these features.
Reading the Original Function
To begin, let's call MessageBoxW to observe its standard, unhooked behavior. Then, I will obtain the address of MessageBoxW using my get_function wrapper, which encapsulates the calls to LoadLibraryA and GetProcAddress.
unsafe ;
let proc_address = get_function?;
The get_function implementation is defined as follows:
GetProcAddress in Rust returns a type-safe function pointer. To work with it more generically as a memory address, I convert it to a raw *const c_void pointer.
Now that I have the address of MessageBoxW, I can prepare to overwrite its code. But before doing so, it's crucial to save the original bytes. This allows for restoring the original function behavior later within my hook routine, if needed.
let ptr = proc_address as *const u32;
let slice = unsafe ;
In this step, the c_void pointer is cast to a *const u32. This is done because ARM64 instructions are fixed at 32 bits, or 4 bytes, in length. By treating the function's code as a sequence of u32 values, the manipulation and reading of these instructions become more straightforward. This approach is in contrast to using u8, which might be more common in x86 architecture scenarios. Because the operation is within the same process, Rust's slices allow for direct memory access, negating the need for ReadProcessMemory to fetch the initial function bytes. The function std::slice::from_raw_parts is used here to create a slice that directly represents the memory at the given address. A significant advantage of this method is that any changes to the underlying memory are instantly reflected in the slice, as it acts as a direct pointer to the raw memory without an intermediary buffer. It's important to keep in mind that any modifications to the memory the slice points to will be immediately visible through this slice.
One might ask, why read exactly four instructions, totaling 16 bytes? Why this specific amount and not something different? This brings us to a necessary discussion about the specifics of the ARM64 instruction set architecture and how detour jumps are implemented on it.
ARM64 specifications
As mentioned earlier, instructions in ARM64 architecture are 32 bits long. The operands for these instructions are encoded directly within those 32 bits. For example, consider the MOVZ instruction. This instruction is used to move a 16-bit immediate value into a register.
There are actually two forms of the MOVZ instruction. One operates on the 32-bit portion of a register, known as a W register, and the other operates on the entire 64-bit register, referred to as an X register. For this discussion, the focus will be on the X register variant.
| 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | - | - | imm16 | Rd |
The table illustrates the bit-level structure of the MOVZ instruction. As can be observed, starting from bit position 20, a 16-bit immediate value is encoded. Further, beginning at bit position 4, the target register, where the 16-bit value will be stored, is also encoded. This is representative of how instructions are encoded in the ARM64 assembly language. Instructions directly embed their operands within these 32 bits. This design simplifies instruction processing, eliminating concerns about padding, and making opcode interpretation relatively straightforward - by examining the 32-bit instruction and performing bitwise operations, the instruction type can be identified.
However, addresses in ARM64 architecture are 64-bit, and as previously mentioned, there are also 64-bit registers. This raises the question of how a 64-bit value can be encoded within a 32-bit instruction. The straightforward answer is: it cannot be done directly. To load a 64-bit value into a register typically requires the use of four separate instructions.
This isn't universally true, as instructions like ADRP (Address to Data Relative to PC) exist. ADRP enables the loading of a 64-bit address into a register using a single instruction by employing addressing relative to the Program Counter (PC). However, it’s important to note that ADRP comes with certain limitations which will be discussed later.
Therefore, in many cases, using a sequence of three instructions is necessary: one MOVZ instruction followed by two MOVK instructions. All of these instructions accept a 16-bit immediate value as an operand. This might lead to the question of how combining three 16-bit values, even with binary shifts, can construct a 64-bit value. In reality, a full 64-bit address isn't always needed because Windows ARM supports 48-bit virtual addresses. Indeed, as detailed here, most Cortex-A processors support mainly 48-bit virtual addresses.
Consider an address such as 0x00007ff7084220d8. This address can be loaded into the X28 register using the following sequence of assembly instructions:
movz x28, #0x20D8
movk x28, #0x842, lsl #0x10
movk x28, #0x7FF7, lsl #0x20
To verify this assembly sequence, examine the following Python snippet.
= 0x20D8
= 0x0842
= 0x7FF7
This Python code snippet effectively mirrors the sequence of presented assembly instructions, demonstrating their logical equivalence.
Returning to the initial question that led to this discussion: why are four original instructions of MessageBoxW read? The reason is that these four instructions will be overwritten with a detour. This detour will consist of:
- Three instructions to load the address of the custom hook routine into the
X28register, utilizingMOVZand twoMOVKinstructions as previously discussed. - A jump instruction, specifically
BR(Branch Register) orRET(Return), which will redirect the execution flow to the designated hook routine.
With the intricacies of ARM64 architecture clarified, let's refocus on the original topic of API hooking and proceed with the practical implementation.
Detour Routine
At this point, the address of MessageBoxW has been obtained, and the initial four instructions of this function have been saved. As a quick reminder, here's the Rust code snippet that accomplished this:
let proc_address = get_function?;
println!;
let ptr = proc_address as *const u32;
let slice = unsafe ;
The next step is to create a detour routine and establish a jump to it. Let's begin by exploring the detour routine itself, as hinted by this section's title.
Hook routines, also known as detour routines – these terms are interchangeable – are functions that will be executed instead of, or in place of, the original MessageBoxW function. These routines house the custom logic intended to be applied either before or instead what would have been a call to the original MessageBoxW.
To simplify things significantly, this detour routine will adopt the exact same function signature as MessageBoxW. This design choice provides direct access to the parameters of MessageBoxW within the detour routine, eliminating the complexities of manually navigating the stack or reading registers to access argument values. Let's look at the Rust code for this detour routine prototype:
As seen, the prototypes for detour_routine and MessageBoxW are identical. Both take the same parameters and specify the same return type. When program execution is redirected to the detour routine, the original parameters passed to MessageBoxW will be readily available as arguments to detour_routine.
Within this detour_routine, a wide range of actions can be performed. Function arguments can be inspected, and specific actions can be triggered based on predefined conditions. For this demonstration, the example focuses on simply printing the arguments passed to the function.
To properly display the text-based arguments of MessageBoxW, the to_hstring function is used. This converts the pointer types (PCWSTR) into Rust's native string type (String). Without this conversion, the code would merely print the memory addresses pointed by these pointers, rather than the actual text content.
Next, the execution will be passed to the original MessageBoxW function, but with a modified message argument. Observe the following code modification to the detour routine:
However, this code introduces an issue. Since the original MessageBoxW is still hooked, calling it directly from the detour routine would inadvertently trigger the detour routine again. This would lead to an infinite recursion and, ultimately, program termination due to a stack overflow. To circumvent this in the naive approach, the original bytes of MessageBoxW are restored just before invoking the actual MessageBoxW function. As these original bytes were preserved in the main function earlier, the next step involves making these bytes accessible within the detour routine so they can be used with WriteProcessMemory to temporarily unhook the function. Given that directly passing data through detour routine parameters isn't straightforward in this context, so a global static variable is employed as a simpler, albeit less ideal, solution for this example.
static HOOKING_DATA: = new;
unsafe
unsafe
The HookingData structure is defined to encapsulate all necessary information required for restoring MessageBoxW's original behavior. Beyond merely storing the byte array representing the original instructions, this structure also includes the memory address of MessageBoxW and a handle to the current process. By storing these values, the detour routine avoids redundant calls to get_function and GetCurrentProcess, optimizing efficiency slightly. Below is the complete implementation of the detour routine within this naive hooking strategy:
To summarize the steps taken so far:
- The memory address of
MessageBoxWwas obtained. - The initial bytes of
MessageBoxWwere saved in a global structure, which is intended for use during the unhooking procedure within the detour routine. - A detour routine for
MessageBoxWwas created. This routine is designed to be executed before the original call toMessageBoxW. In this naive approach, the detour routine also shoulders the responsibility of temporarily unhookingMessageBoxW.
The final element yet to implement is the code responsible for redirecting execution to this detour routine whenever MessageBoxW is invoked. This is where the detour jump mechanism comes into play.
Detour jump
A detour jump's nature has been previously described in detail earlier in the document. The objective now is to generate a specific sequence of assembly code and use it to overwrite the initial bytes of MessageBoxW. This assembly code, representing the detour jump, is as follows:
mov x28, #0x20D8
movk x28, #0x842, lsl #0x10
movk x28, #0x7FF7, lsl #0x20
ret x28
To achieve this, ARM64 assembly specifications along with bitwise operations will be employed to construct the necessary machine code. To generate this detour jump, the memory address of the detour_routine, represented as a 64-bit value, is required. The subsequent Rust snippet retrieves this address:
let hook_routine_address = .;
let offset = hook_routine_address as isize;
Now, let's delve into the process of generating the ARM64 assembly instructions. Initially, some constant values are defined, representing fundamental ARM64 operations and the registers utilized in the detour jump:
const MOVZ: u32 = 0xD2800000;
const MOVK: u32 = 0xF2800000;
const RET: u32 = 0xD65F0000;
const X28: u32 = 0x1c;
const LOW: u32 = 0b01;
const HIGH: u32 = 0b10;
const RET_X28: u32 = RET | ;
Because both MOVZ and MOVK instructions expect a 16-bit immediate value as their operand, the 48-bit address must be divided into three 16-bit chunks. (For context on why the address space is considered 48-bit rather than 64-bit in this scenario, refer back to the chapter on ARM64 specifications). The following code segment accomplishes this splitting:
let x = as u32;
let y = as u32;
let z = as u32;
Next, the ARM64 instructions are encoded based on these components and stored in an array:
let movz = MOVZ | | X28;
let movk_lo = MOVK | LOW << 21 | | X28;
let movk_hi = MOVK | HIGH << 21 | | X28;
let detour_jump_bytes = ;
Finally, the original MessageBoxW function in memory is overwritten with the generated detour jump using WriteProcessMemory:
unsafe
Now, with this detour jump in place, initiating a call to MessageBoxW will directly transfer program execution to the detour routine.
Trampoline Hooking
A more sophisticated and improved method compared to the naive hooking approach is trampoline hooking. This technique utilizes a "trampoline" to facilitate the jump back to the original function from the detour routine. In contrast to the naive method, trampoline hooking avoids the need for the detour routine to perform an unhooking procedure that restores the original instructions of the hooked function each time. The naive approach, while conceptually simple, has inherent drawbacks, which were detailed in a dedicated section. In this section, I will guide you through implementing a more robust hooking mechanism inspired by, but not exclusively limited to, the design principles found in Microsoft Detours. Trampoline hooking is actually a widely adopted and preferred strategy for function hooking in general.
Trampoline Explained
Before diving into the code itself, let's clarify what a "trampoline" is and how it works. Imagine a trampoline as a mini-program created on-the-fly, specifically designed to execute the code that was initially overwritten when you placed your hook. It performs essentially two crucial operations:
- Executes the Replaced Instructions: It runs the original instructions of the hooked function that were displaced by the detour jump.
- Jumps Back Judiciously: After executing these original instructions, it intelligently jumps back into the hooked function, but not at the very beginning (which would cause a loop!). Instead, it jumps to a point in the original function just after the area that was overwritten by the hook.
Refer back to the "Hooked vs. Unhooked function call" diagram presented at the start of this post. Let's use it to visualize how a trampoline operates.
As depicted, when the Foo function is hooked, its first two instructions aren't simply discarded. Instead, they are preserved and relocated to the trampoline. When Foo is called, execution jumps to FooHook (the detour routine). FooHook might modify the arguments meant for Foo (in the example, replacing them with 0), and then, crucially, it doesn't directly call Foo again. It jumps to the trampoline. Within this trampoline reside the two original instructions of Foo: mov rax, rdi and add rax, rsi. These instructions are executed first. Only after these original instructions have run does the trampoline then jump back into the Foo function. However, it doesn't jump back to the very start of Foo, but precisely after the initial detour jump instructions. This ensures the rest of the original Foo function executes normally, after the trampoline has handled the initial overwritten part.
This mechanism thoughtfully preserves the intended behavior of the original Foo function. In our simplified example, nearly all of Foo's logic is contained within these first two instructions, so almost the entire function's behavior is executed inside the trampoline. However, in more complex scenarios, the trampoline typically contains only a small set of the hooked function's initial instructions – just enough to cover what was overwritten by the detour jump. In straightforward cases, like our Foo example, recreating the trampoline is mainly a matter of copying instructions directly. They perform the same operation in the trampoline as they would in their original location. However, instructions that rely on Program Counter (PC) relative addressing, like ADRP or CBZ in ARM64, require more careful handling, a point we'll revisit shortly.
Jumping Back into the Hooked Function
Once the trampoline has executed the original instructions from Foo, the execution needs to return into the flow of the original Foo function. It's vital not to jump back to the very beginning of Foo, as this would re-trigger the detour jump, leading to infinite recursion – a program's worst nightmare! Instead, the trampoline must jump to Foo + offset. Here, "offset" represents the number of bytes in the original Foo function that were replaced by the detour jump code. Effectively, you need to calculate the address in Foo that is immediately after the detour jump. This is why the final instruction in the example trampoline is jmp Foo+6. The instructions mov rax, rdi and add rax, rsi together occupy 6 bytes. In the ARM64 world, this offset will always be a multiple of 4 since ARM64 instructions are always 4 bytes in size.
Generating a Trampoline
To create a trampoline, you need to replicate the original instructions of the hooked function, and then append a jump instruction to redirect execution back into the hooked function at the correct offset. A challenge arises because some original instructions cannot be directly copied. Specifically, instructions employing program counter relative addressing pose a problem. Consider again the MessageBoxW function:
USER32!MessageBoxA:
00007ffb`a73904a0 f0000888 adrp x8,USER32!gSharedInfo+0x20 (00007ffb`a74a3000)
00007ffb`a73904a4 b945a908 ldr w8,[x8,#0x5A8]
00007ffb`a73904a8 34000168 cbz w8,USER32!MessageBoxA+0x34 (00007ffb`a73904d4)
00007ffb`a73904ac aa1203e8 mov x8,xpr
00007ffb`a73904b0 f940250a ldr x10,[x8,#0x48]
00007ffb`a73904b4 900008a8 adrp x8,USER32!WPP_MAIN_CB+0x18 (00007ffb`a74a4000)
00007ffb`a73904b8 911b0109 add x9,x8,#0x6C0
00007ffb`a73904bc d2800008 mov x8,#0
In our example, the detour jump we're using might be 4 bytes in size. This jump would overwrite the first few instructions at the beginning of MessageBoxW. Examining the disassembled MessageBoxW, we see instructions like adrp, ldr, cbz, and mov might be affected. Upon closer inspection of the ARM documentation, you'll find that instructions like adrp and cbz both utilize PC-relative addressing. cbz, for instance, has limitations on the distance to the target label of its conditional jump. The challenge here stems from the fact that in my implementation, the trampoline is intended to reside on the heap, at an address dynamically allocated by the operating system. Because of this allocation potentially being far from the original MessageBoxW code, the PC-relative addresses encoded in adrp and cbz are likely to become invalid when simply copied to the trampoline. While it's theoretically possible to strategically place the trampoline in memory to maintain the usability of PC-relative jumps (and Microsoft Detours seems to employ such techniques, for simplicity in this explanation, I'll proceed with locating the trampoline on the heap. Interestingly, Microsoft Detours itself also includes "heap trampline" implementations and even maintains a list of "problematic instructions" that necessitate special handling when a trampoline is located at a distance from the original code. Therefore, handling adrp and cbz (and similar PC-relative instructions) requires additional processing to ensure the trampoline functions correctly. In the following subsections, we'll explore a potential approach to address this challenge.
Patching ADRP
Let's first tackle the adrp instruction because it's the first hurdle when dealing with PC-relative addressing. This instruction turned out to be quite intricate and initially a bit puzzling. However, this insightful article was invaluable in deciphering its operation.
In essence, adrp is designed to calculate and store a memory address into a designated register. This address isn't absolute; instead, it's computed dynamically based on the Program Counter (PC) – which, at the point of execution, holds the address of the adrp instruction itself – and a special immediate value embedded within the adrp instruction. This immediate value is not directly used as is; it represents a shift in terms of memory pages. Specifically, this immediate is multiplied by 0x1000 (which is 4096 in decimal), the size of a memory page. Finally, adrp zeroes out the lower 12 bits of the resulting calculated address.
Let's solidify this with a practical example. Consider this adrp instruction:
00007ff8`3f27fe20 b0000888 adrp x8,USER32!gSharedInfo+0x20 (00007ff8`3f390000)
While a debugger conveniently resolves and displays the final address that adrp will compute and store in the x8 register (as shown in the comment 00007ff83f390000), it's important to understand the calculation process ourselves. Let's break down how this address is actually derived. Under the hood, the adrp instruction is encoded in a specific binary format that the processor interprets to perform these steps. Understanding this encoding will be key to patching it correctly.
| 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | immlo | 1 | 0 | 0 | 0 | 0 | immhi | Rd |
In the given example, the adrp opcode is 0xb0000888. When this opcode is broken down into its binary components, it reveals the following structure:
1 01 10000 0000000000001000100 01000
From this binary representation, the immediate value can be extracted as 100010001, which corresponds to 273 in decimal. This decimal value signifies the page shift, and as such, it is multiplied by 0x1000. Once the shift value is obtained, and with access to the adrp instruction's address, the address calculation can be performed.
The formula used for this calculation is:
(adrp address + shift value * 0x1000) & 0xFFFFFFFFF000
The bitwise AND operation with 0xFFFFFFFFF000 effectively clears the least significant 12 bits of the resulting address. Applying the data from our example, the formula becomes:
(0x00007ff83f27fe20 + 273 * 0x1000) & 0xFFFFFFFFF000
The result of this computation is 0x7ff83f390000, which aligns with the address value resolved by the debugger.
As previously mentioned, when a trampoline is located on the heap, the physical distance may become too large for the adrp instruction to operate as intended. Specifically, the immediate value within the adrp instruction might not be sufficient to reach the target address over such a distance. Consequently, a decision was made to emulate the functionality of the adrp instruction. This emulation involves replacing the adrp instruction with a sequence of a movz instruction followed by two movk instructions. Emulating adrp in this context refers to pre-calculating the address that the adrp instruction would generate, using the method detailed earlier. To facilitate this, a patch_adrp function was implemented. This function takes the adrp instruction's address and its opcode as input, and, based on these inputs, it generates the appropriate mov instructions. These mov instructions are designed to load the calculated address into the register originally targeted by the adrp instruction.
Patching CBZ
The CBZ instruction, in contrast to ADRP, is simpler to grasp. It performs a straightforward check: it examines whether the value in a specified register is zero. If the register's value is indeed zero, a jump to a target location is executed. To patch this instruction for use in a trampoline, a similar strategy to the adrp patching is adopted. To preserve the target address of the original CBZ instruction, the address of the CBZ instruction within the original function is taken as a starting point, and the target address is calculated based on the instruction's encoding. Then, to replicate the branching behavior in the trampoline, the calculated target address needs to be loaded into a register, again employing the three mov instruction sequence (movz and two movk). Finally, a BR (Branch Register) instruction is added to effect the jump to this loaded address.
To handle the conditional check inherent in CBZ (the "check if zero" condition), the CBNZ (Compare Branch if Not Zero) instruction is leveraged. CBNZ effectively inverts the condition. Thus, in the trampoline, a CBNZ will be used to check the condition; however, to maintain the original logic of CBZ, the code flow needs to be inverted in the patching logic to ensure the jump happens under the same conditions as the original CBZ. This approach ensures that the jump is triggered if the condition is met, mirroring the original CBZ instruction's behavior, albiet with a reversed check and jump logic in the trampoline to achieve the same outcome.
The diagram below visualizes this patching approach for CBZ:

If the original CBZ condition is met (value is zero), execution will branch out of the trampoline and proceed to the intended location within the hooked function, just as the original CBZ would have directed program flow.
The following function illustrates the implementation of CBZ patching:
Processing Other Instructions
While CBZ and ADRP need special handling, many ARM64 instructions don't. For this explanation, patching is implemented only for ADRP and CBZ. For a complete list of instructions needing special handling, refer to Microsoft Detours.
For most other instructions, a simple copy into the trampoline is sufficient. These instructions, unlike ADRP and CBZ, are often not PC-relative or use absolute addressing. This means their functionality remains the same regardless of their location in memory. Thus, direct copying works effectively, simplifying trampoline creation for the majority of code.
Generating the Jump Back to the Hooked Function
Finally, to complete the trampoline, a jump back to the original hooked function is needed. This jump is created using the following function:
This final jump instruction ensures that after the trampoline executes the necessary original code program flow seamlessly returns to the original execution path of the hooked function, right after the point where the detour was initially placed.
Function for Trampoline Generation
To summarize the process, let's look at the function responsible for generating the trampoline. This function is designed to take the original instructions, which were overwritten by the detour jump, along with their original addresses. It then iterates through each instruction, applying the specific processing logic discussed earlier. This involves identifying instructions like cbz and adrp for specialized patching.
Crucially, this function also requires the address to which the trampoline should jump back. This "return address" is precisely the address of the instruction in the original function that immediately follows the detour jump.
In essence, this function orchestrates the entire trampoline creation: from analyzing and patching individual original instructions to constructing the essential jump instruction that bridges the execution back into the normal flow of the original, hooked function.
Invoking the Trampoline
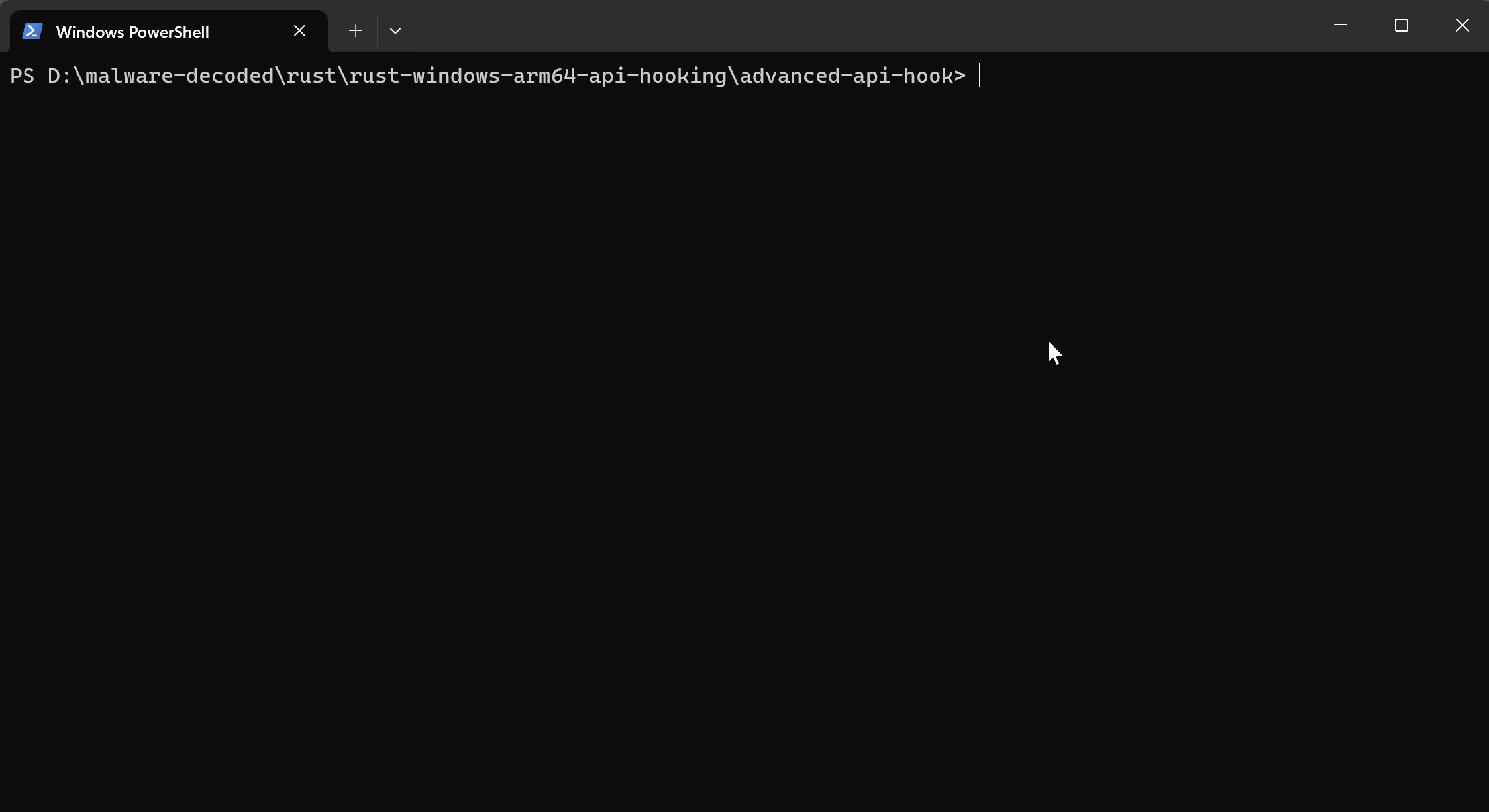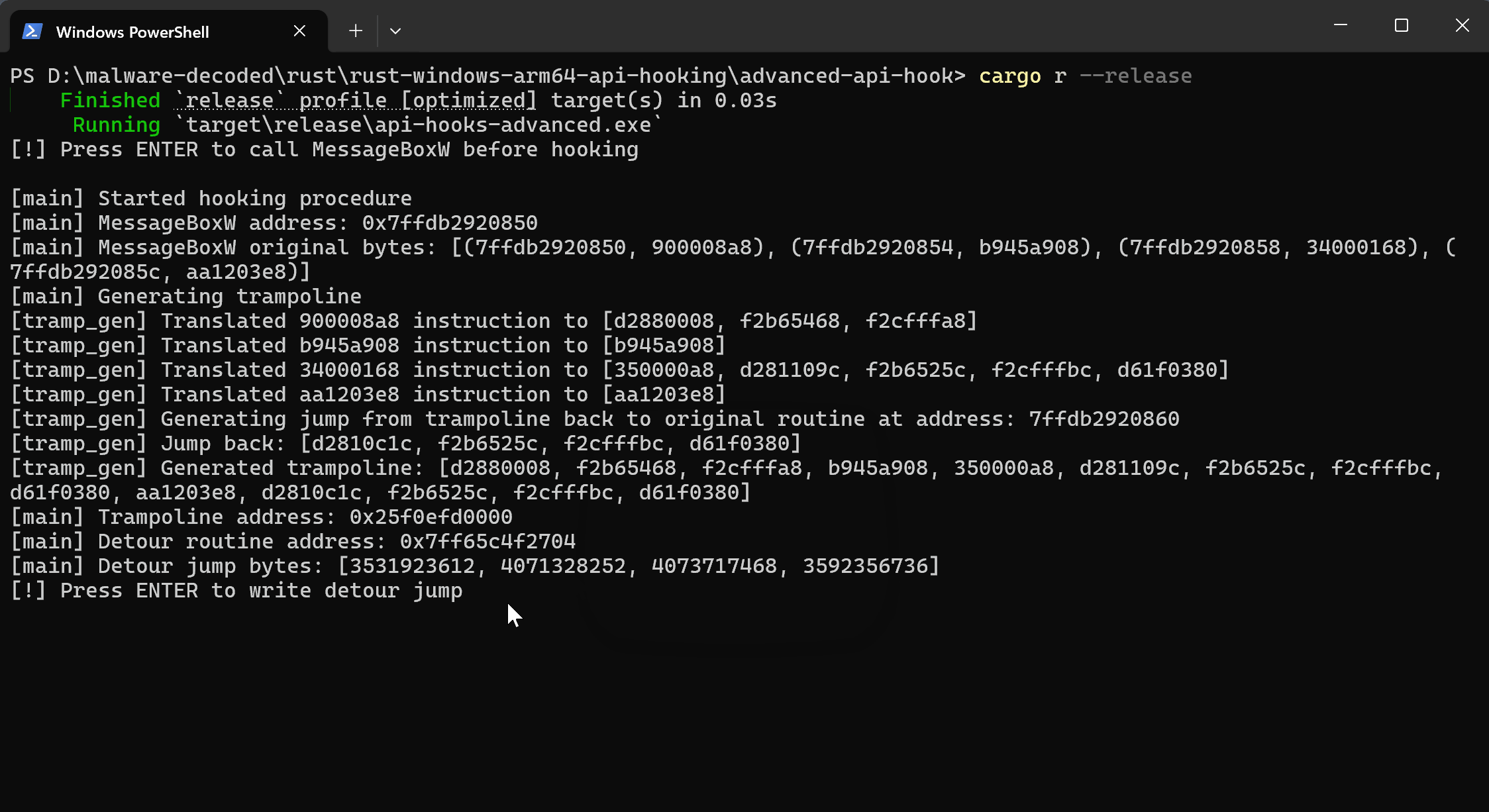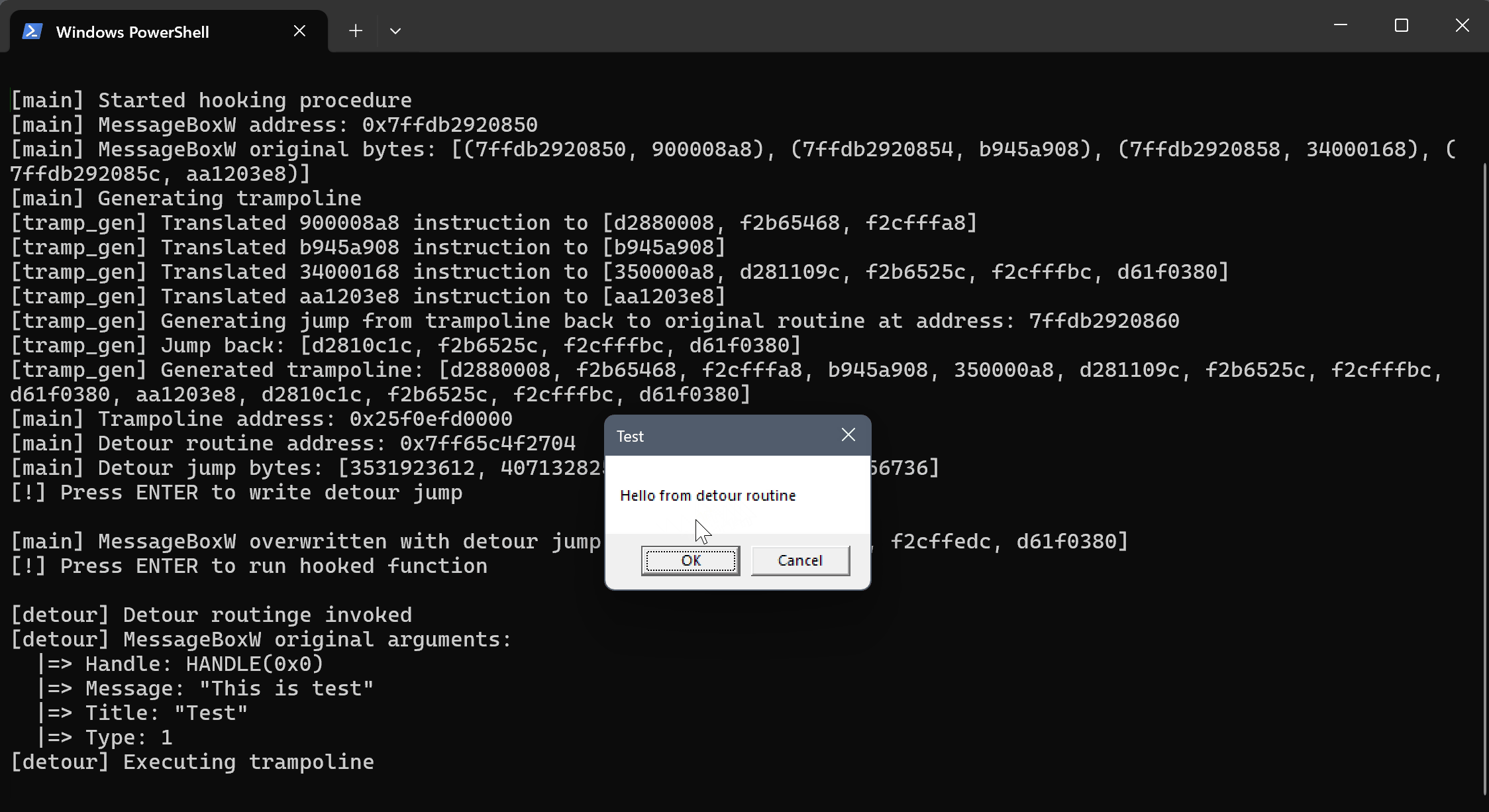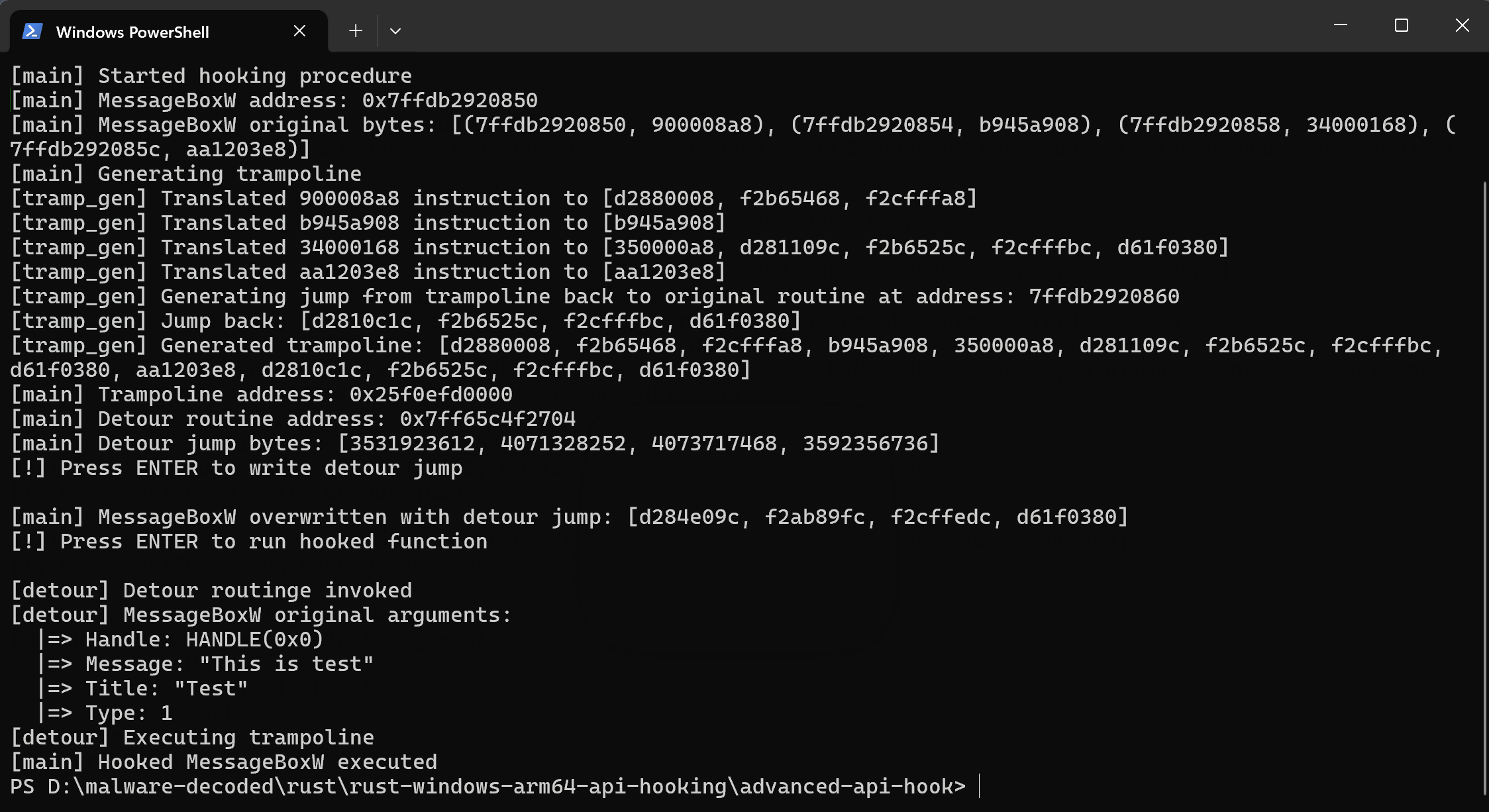
With the trampoline successfully generated, the next step is to put it to work within the detour routine. The function responsible for generating the trampoline provides a crucial piece of information: the memory address where the newly created trampoline resides. Now, instead of directly unhooking and restoring original bytes as done in the naive approach, this trampoline address takes center stage.
This trampoline address is then converted into a function pointer. Interestingly, this function pointer (exec_trampoline in the code) is intentionally designed to have the same function prototype as the original MessageBoxW. Why is this important? This matching prototype is key to simplifying argument handling. By ensuring the trampoline function expects the same arguments as MessageBoxW, there's no need to manually juggle registers or memory locations to access or modify MessageBoxW's parameters within the detour routine. It streamlines the process significantly.
Wrapping up
To put it all together, here's how the main function looks for the trampoline hooking implementation:
static TRAMPOLINE_ADDR: = new;
And this is a demonstration of the trampoline hooking program in action. Observe how the detour routine intercepts the MessageBoxW call, prints the arguments, and then allows the original MessageBoxW functionality to proceed via the trampoline, but with a modified message.
Sources
- ARM Developer Documentation
- AArch64 Instruction Encoding CSV
- Microsoft Detours Example Repository
- Microsoft Detours
- ARM64 Relative References Blog Post
- x86 API Hooking Demystified Blog Post
- Code Reversing: Dumping and Disassembling Obfuscated Code - Part 1
- Stack Overflow: Semantics of ADRP and ADRL Instructions in ARM Assembly